GraphQL
GraphQL 是一种查询语言和执行引擎,通过 API 描述应用程序数据模型的功能和需求。2012 年由 Facebook 提出并实现,最初用在移动端,在 2015 年对外发布。于 2019 年成立 GraphQL 基金会发展至今。
简介

GraphQL 可以类比 SQL(Structured Query Language), 都是一种查询语言,通过查询语句可以获得期望结果。不同之处有两点:
SQL是基于结构化的数据模型,而GraphQL基于图。SQL是从数据库查询,而GraphQL从服务器查询。
为什么 GraphQL 基于图?
因为大多数应用程序数据模型基于图。以博客系统为例,一个作者可以撰写多篇博客,同一个博客也可以由多个作者共同完成,如果两个作者写过同一篇博客,那么他们互为合作者。博客和作者是实体,属于图的节点。作者和博客之间(多对多)的关系,属于图的边。特别的,实体和他们属性之间的关系也属于边,属性内容为叶子节点。如下图所示:
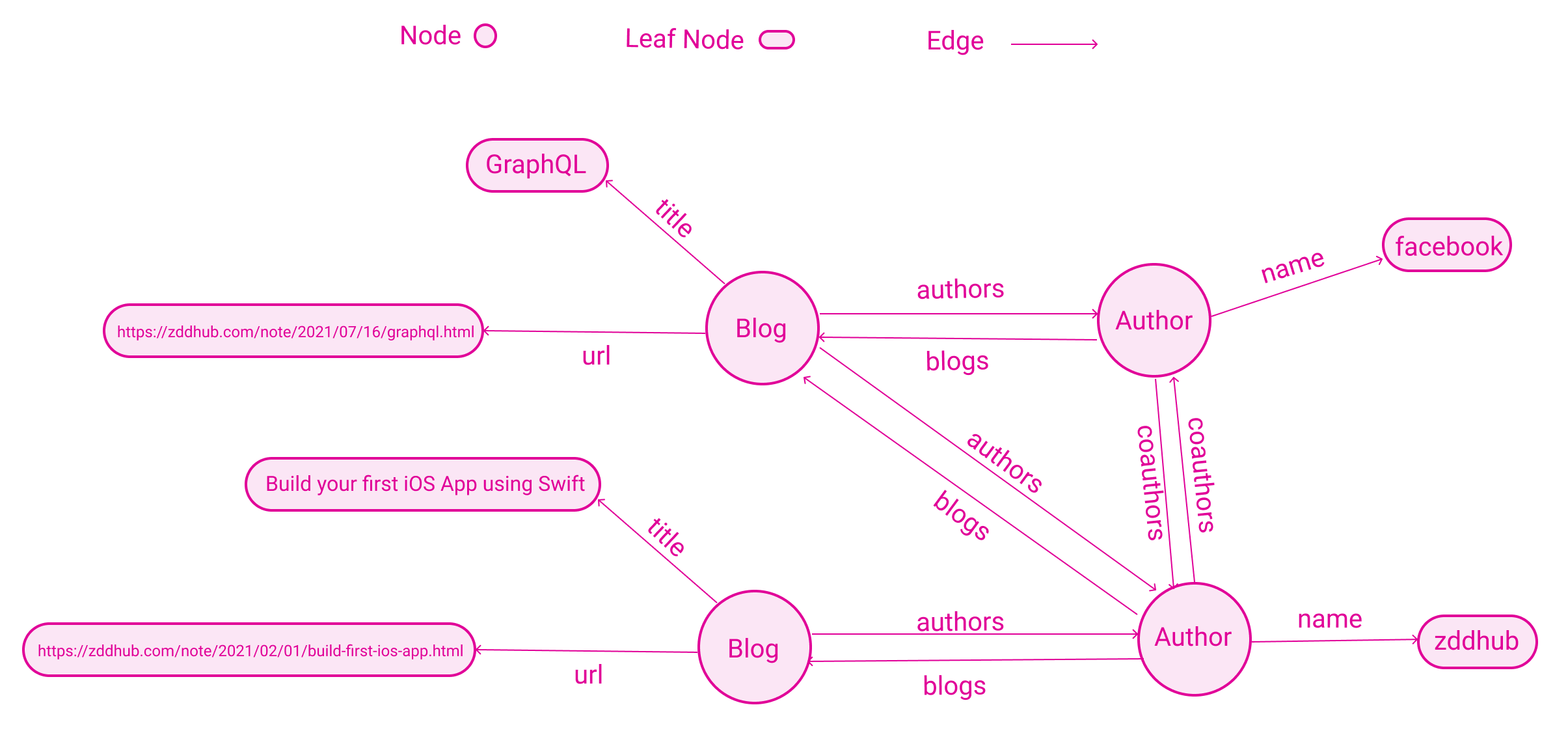
很明显这是一个双向循环图,GraphQL 就是基于这种典型的图模型,来构建和查询数据。
核心概念
GraphQL 构建在 API 之上,通过 API 在客户端——服务器端交换数据,它使用一个模式定义语言(The Schema Define Language)来描述对数据的增删查改。
模式定义语言 The Schema Define Language (SDL)
GraphQL 是如何来描述应用程序数据模型的呢?它使用类型系统来描述实体,使用类型之间的关系来描述实体之间的关系。比如文章开始的博客系统,对应 Schema 如下:
type Blog {
id: ID
title: String
url: String
authors: [Author]
}
type Author {
id: ID
name: String
coauthors: [Author]
blogs: [Blog]
}
定义了两个类 Blog 和 Author 来描述博客和作者这两个实体,用属性相互引用来表示博客和作者之间多对多的关系。
查询数据
简单博客应用程序的数据模型是一张图,一张双向循环图。对于复杂的大型应用程序,它的数据模型可能包含成百上千个节点和边,一次查到整张图显然是不合适的。GraphQL 需要确定两件事:
- 查询的入口
- 如何遍历图以获取数据
它通过定义 Query 来实现。Query 的不同方法 (Resolver) 确定了查询的入口和遍历的方法。 如果你想查询系统中所有博客, 你可以:
- 直接找到博客节点查询,例如:

对应的查询语句如下:
query {
blogs {
title
url
}
}
查询结果为:
{
"data": {
"blogs": [
{
"title": "GraphQL",
"url": "https://zddhub.com/note/2021/07/16/graphql.html"
},
{
"title": "Build your first iOS App using Swift",
"url": "https://zddhub.com/note/2021/02/01/build-first-ios-app.html"
}
]
}
}
查询语句开头的 query 可以省略。查询结果和 query 结构十分相似,返回结果放在 data 下。需要在 Schema 中定义 Query 语句来支持这种查询。如下:
type Query {
"Query Blogs directly"
blogs: [Blog]
}
这里的 blogs 就是查询入口,客户端通过这个入口来获取数据,服务器端通过这个入口来准备数据。
- 通过作者节点查询博客,例如:

对应的查询语句如下:
{
authors {
name
blogs {
title
url
}
}
}
查询结果为:
{
"data": {
"authors": [
{
"name": "zddhub",
"blogs": [
{
"title": "GraphQL",
"url": "https://zddhub.com/note/2021/07/16/graphql.html"
},
{
"title": "Build your first iOS App using Swift",
"url": "https://zddhub.com/note/2021/02/01/build-first-ios-app.html"
}
]
},
{
"name": "facebook",
"blogs": [
{
"title": "GraphQL",
"url": "https://zddhub.com/note/2021/07/16/graphql.html"
}
]
}
]
}
}
通过遍历所有 blogs 字段去重后拿到所有博客信息。仍然需要在 Schema 中定义 Query 语句来支持这种查询,如下:
type Query {
"Query Blogs via authors"
authors: [Author]
}
你可能觉得这种方法比较傻,但是不可否认通过它仍然能拿到数据。如果加上业务场景,就会变的更有意义,例如查询某个作者的所有博客,GraphQL 也是支持这种的,通过给 Query 根节点增加参数的办法来实现。
带有参数的 Schema 如下:
type Query {
"Query Blogs via authors"
authors(authorId: ID): [Author]
}
对应的查询语句为:
{
authors(authorId: "57cbf211-3117-4f5e-99c5-6fe48696c20d") {
name
blogs {
title
url
}
}
}
当 authorId 缺省时查询所有作者以及名下的博客。当 authorId 存在时,只查询当前作者名下的博客。
除了直接使用 authorId,我们还可以定义一个变量,来让 Query 支持任意的 authorId,对应的查询语句如下:
query GetAuthors($authorId: ID){
authors(authorId: $authorId) {
name
blogs {
title
url
}
}
}
与此同时,需要定义一个 Query varibles 把值传给 GraphQL。
{
"authorId": "57cbf211-3117-4f5e-99c5-6fe48696c20d"
}
- 当然你还可以在图里绕几圈玩玩,再获取数据(不考虑性能),例如:

{
authors {
name
blogs {
authors {
blogs {
title
url
}
}
}
}
}
通过给定的 Query Schema,你可以自由选择查询根节点并制定遍历策略。GraphQL 在图中遍历后,结果通过树返回。例如上述例子中,authors -> blogs -> authors -> blogs, 查询结果通过增加新的子节点而不是循环引用,以树的格式返回,简化了数据的抽象。

修改数据
GraphQL 是一种 API 的设计模式,API 支持增删查改,刚介绍了查询,现在来说说修改。GraphQL 使用 Mutation 来支持对数据的修改,包括:
- 创建数据
- 更新数据
- 删除数据
例如, 下面这个 Schema 定义了对 Author 的增删和更新操作:
type Mutation {
createAuthor(name: String): Author
deleteAuthor(id: ID): Author
updateAuthor(id: ID, name: String): Author
}
对应的创建语句为:
mutation {
createAuthor(name: "zddhub") {
id
name
}
}
期望的结果:
{
"data": {
"createAuthor": {
"id": "57cbf211-3117-4f5e-99c5-6fe48696c20d",
"name": "zddhub"
}
}
}
更新后删除:
mutation {
updateAuthor(id: "57cbf211-3117-4f5e-99c5-6fe48696c20d", name: "zdd") {
id
name
}
deleteAuthor(id: "57cbf211-3117-4f5e-99c5-6fe48696c20d") {
id
name
}
}
注意,GraphQL 支持同时查询或者修改多个根节点,这也进一步体现了 Graph 的精髓。
实时更新订阅
在某些业务场景下,客户端需要和服务器端保持长连接,当特定 event 发生后,服务器端实时通知客户端。GraphQL 使用 subscription 来支持这种场景。
例如:
subscription {
newAuthor {
name
}
}
当服务器端新添加 Author 后,客户端将会监听到对应消息。
使用场景
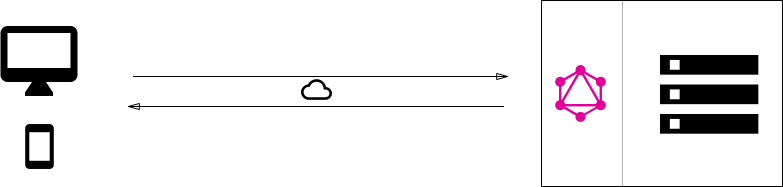
GraphQL 适用于三种场景:
- 直连数据库:对于新项目, 可以优先考虑使用
GraphQL
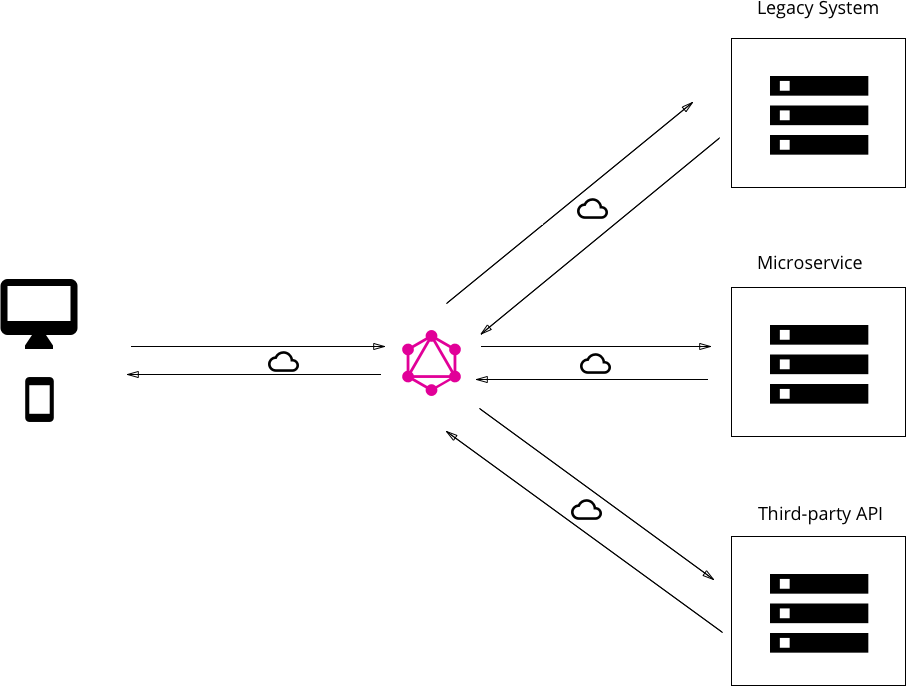
- 集成多个已有系统:尤其微服务被滥用的今天,一个公司存在数十个甚至上百个子系统,用一个设计精良的
GraphQLAPI 把这些子系统屏蔽在后台,能起到很好的隔离作用。
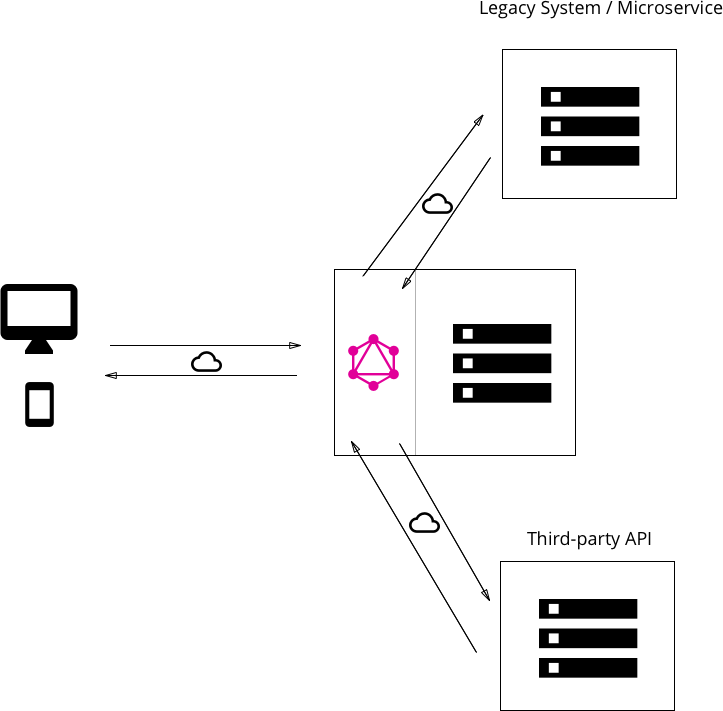
- 数据库和遗留系统混合,将前两种方法混合。当服务器接收到消息时,它将解析查询,并从连接的数据库或者子系统中检索所需的数据。
GraphQL查询之旅
你真优秀能坚持读到这里!上面我们已经介绍了 GraphQL 的基本概念,用法和使用场景,对 GraphQL 这个查询语言已经有一定了解,那么从一个写好的 GraphQL 查询语句到最终得到结果之间,到底会经历怎么样的过程呢?现在让我们看看执行引擎部分。

客户端
首先,由客户端撰写 query 查询语句,例如查询博客的 GraphQL,
{
authors(authorId: "123") {
name
blogs {
title
url
}
}
}
然后,再由客户端把该 Query 语句封装成 Request 请求发给服务器。如果用 curl 命令的话,应该是这个样子:
# POST
curl 'http://localhost:4000/' -H 'Content-Type: application/json' --data-binary '{"query":"{\n authors(authorId: \"123\") {\n name\n blogs {\n title\n url\n }\n }\n}\n"}'
# 或者 GET
# encodeURI('http://localhost:4000/?query={\n authors(authorId: \"123\") {\n name\n blogs {\n title\n url\n }\n }\n}\n')
curl http://localhost:4000/\?query\=%7B%0A%20%20authors\(authorId:%20%22123%22\)%20%7B%0A%20%20%20%20name%0A%20%20%20%20blogs%20%7B%0A%20%20%20%20%20%20title%0A%20%20%20%20%20%20url%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D%0A
在实际使用中,GraphQL 周边的库会帮我们做这些事情。在前端我们只需要撰写 Query 语句就好。
服务端
在服务端接到请求后,经过以下步骤:
- 解析
GraphQL语句 - 构建抽象语法树
- 校验
GraphQL语句是否合法 - 如果不合法,直接返回 bad request 并给出错误信息,如果合法,继续下一步
- 使用解析函数获取查询数据 ⭐️
- 组装结果并返回
在实际使用时,GraphQL 后端的库会帮我们做大部分的工作,只把使用解析函数获取查询数据给我们。解析函数类似路由,回答了数据从哪里来的问题,是真正有业务价值的部分。
解析函数 Resolver Functions
GraphQL 定义的每个 type 都有自己的 Resolvers 方法,用来解析自己的所有属性。每个属性都可以对应一个 resolver,如下图所示:
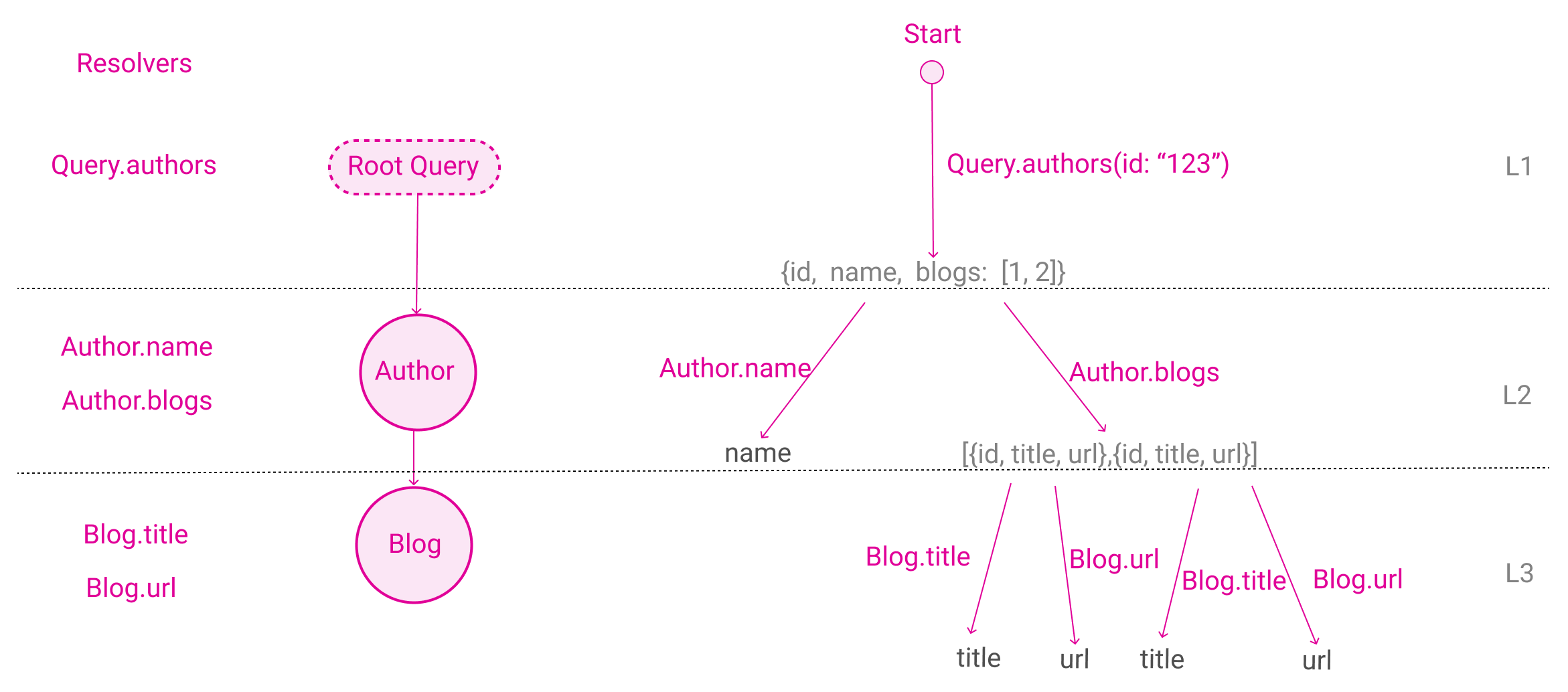
之前说过,GraphQL 从图中检索出一棵树返回给前端。从 Query.authors 开始,一层一层的 resolve,直到所有查询值全部被解析出来为止。
注:虽然支持但不一定非得给每个属性写 resolver,实际中服务端会实现默认版本并做各种优化。
解析函数的定义如下:
resolver: (parent, args, context, info) => {}
它含有四个参数:
- parent: parent 是父节点的解析后的值,包含父节点解析后的信息
- args:
GraphQL里传过来的参数 - context:context 是共享数据,在多个 resolver 之间共享,比如数据库的连接,认证信息等
- info:包含有关操作执行状态的信息,包括字段名、从根到字段的路径等
安全策略
认证和授权(Authentication and Authorization)
对 API 来说认证和授权是最常用的安全策略,认证解决你是谁的问题,而授权负责监管你能干什么。
对 GraphQL 来说认证选择 http 协议常用的做法,比如 OAuth。而把授权放在业务层做。
安全风险和解决方法
GraphQL 提供了强大灵活的数据检索方案,非常适合客户端使用。它为客户端提供了更多的功能,也暴露了更多风险。如果用户恶意的使用 Query 语句,例如构造足够慢 Query 语句等,很容易拖垮服务器。一般来说,服务器端采用以下策略来避免风险。
| 安全风险 | 解决方法 | 优点 | 缺点 |
|---|---|---|---|
| 查询内容太多,或者查询过慢 | 设置超时 | 有效 | 在超时之前损害有可能已经完成,很难超时时间 |
| Query 层数太深 | 限制最大查询深度 | AST 能在执行前检测出问题,拒绝该请求 | 通常不足以覆盖所有滥用的查询 |
| Query 太复杂 | 限制查询复杂度 | 覆盖更多情况,在执行前检测并拒绝请求 | 实现有难度 |
| 调用频繁 | 节流 | 能方式用户频繁访问 | 复杂 |
这些方法可以保护 GraphQL 服务器不受影响,但是没有一种方法是万能的。重要的是要知道哪些选项是可用的,知道它们的限制,这样我们才能做出最好的决定。
缓存
对 GraphQL 来说,服务器端缓存一直是个难题。缓存一般在客户端进行。在客户端,由于 GraphQL 总是从图中返回一棵树,让缓存变得容易。以 Apollo Client 为例,做以下假设来缓存数据:
- 相同的路径,数据相同
query particularAuthor {
author(name: "zddhub") {
name
}
}
query authorAndBlog {
blogs {
title
}
authors(name: "zddhub") {
name
age
}
}
第二个查询没有必要再次查询作者的信息,因为相关信息的值已经在第一次查询中返回。
- 当路径假设不够时,使用对象标识符(object identifiers)
常用的对象标识符是 id,服务器端为了便于客户端缓存,给每个对象分配一个唯一的标识符,如 id。客户端看到相同 id 时,就认为对应的数据是完全相同的。
- 保持查询结果的一致性
如果发现某个缓存的字段做了 Mutation 操作,那么立即放弃该缓存。
REST VS GraphQL
围绕 API 的技术有很多,如下所示:
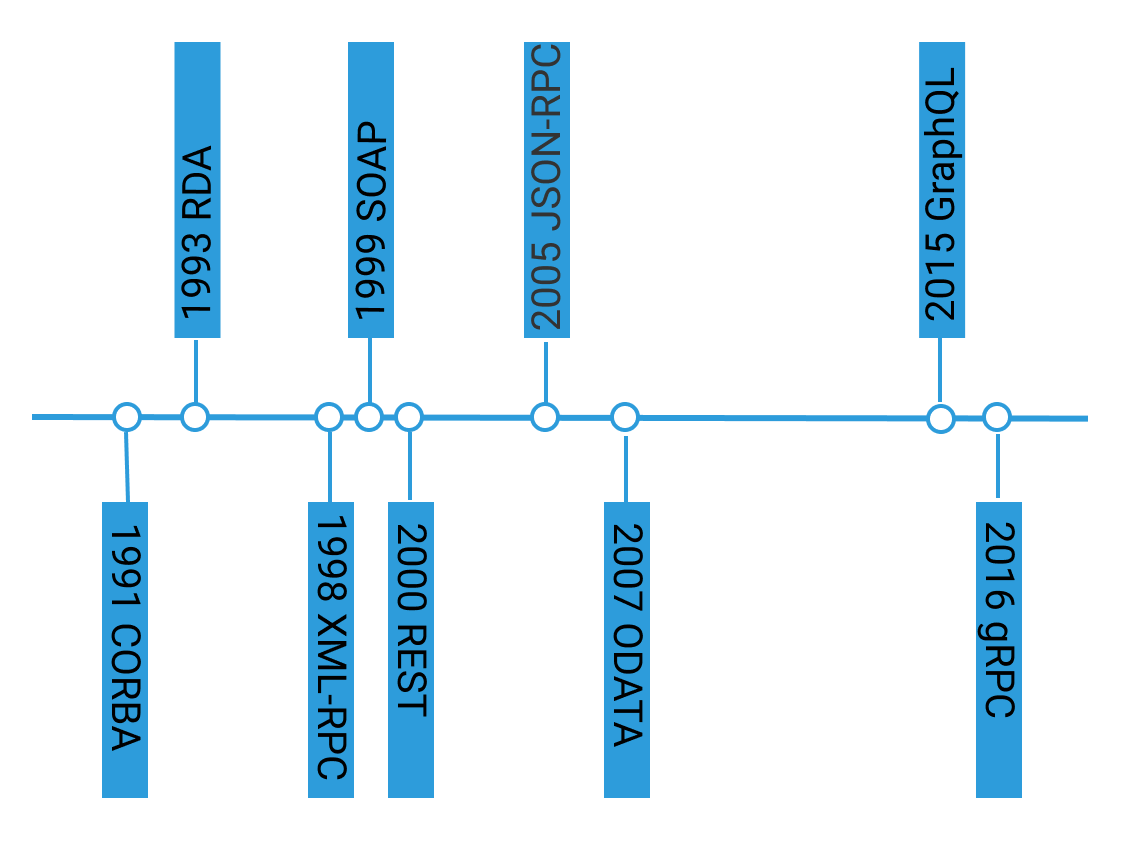
2000 年出现的 REST 因为 无状态和结构化数据 被广泛使用,Ruby On Rails,Nodejs 等框架更是进一步给行业科普了 REST 的概念。以下是 REST 和 GraphQL 的比较:
| REST | GraphQL | |
|---|---|---|
| 类型定义 | No | Yes |
| 抽象的数据模型 | Resources | Graph |
| 自省 | No | Yes |
| Data Type | Week | Strong |
| Real-Time | No | Yes |
| Versioning | Yes | No |
| Overfetching | Yes | No |
| Underfetching | Yes | No |
练习
网上得来终觉浅,绝知此事要躬行。这里有一个设计很好的 GraphQL 练习教程 —— Learn GraphQL with Apollo,感兴趣的同学可以私下练习。
参考资料
- GraphQL Specification
- How to graphQL
- Learn GraphQL with Apollo
- GraphQL Concepts visualized
- GraphQL explained
- GraphQL, gRPC or REST? Resolving the API Developer’s Dilemma - Rob Crowley
- Building Modern APIs with GraphQL
如果你喜欢这篇文章,欢迎赞赏作者以示鼓励

